Hugging Face Hub State 2026: Qwen Leads, Apache 2.0 Wins
Hugging face hub state 2026: Qwen leads at 399M downloads, Apache 2.0 covers 49% of top-1k licenses, top-5 orgs concentrate 46% of all volume.
The hugging face hub state in 2026 looks structurally different from twelve months ago. We pulled the metadata for the 1,000 most-downloaded models on Hugging Face. The leader is not Meta, Google, or OpenAI: it is Qwen (Alibaba), with 399.4M downloads across its top models, 18.5% of all top-1k traffic and nearly 4× Google's footprint on the Hub. 71.5% of top models ship under a permissive open license, with Apache 2.0 alone owning 49%. The top 5 organisations now concentrate 46.1% of all top-1k downloads, and the top 10 hit 58.5%. Eastern orgs together pull 24.1% of total volume, up sharply from a single-digit share in early 2025.
Key findings
- Qwen dominates HF downloads with 399,454,717 on its top models. Across the top 1000 models tracked.
- 71.5% of top-1k models ship under a permissive license. Most common: apache-2.0 (490 models).
- Sub-7B models make up 40.7% of size-named models. Inferred from model id; 351/1000 models declare a size.
- The leading modality is text-generation with 222 top models. Among the top 10 pipeline_tag categories on the Hub.
Why this matters
The Hugging Face Hub is the closest thing the open-source AI world has to a market. Lifetime downloads measure where research, fine-tunes, and product experiments accumulate. Two structural facts jump out of this snapshot of the hugging face hub state in 2026.
First, the open-source center of gravity has shifted east. A single Chinese lab (Qwen / Alibaba) now sits where Meta sat 18 months ago, and the Eastern-org cluster as a whole controls a quarter of the basket. Western labs whose strategy still depends on closed-weight Hub releases are losing mindshare against an Apache 2.0 wave they did not start. Second, the modal-size narrative, popularised by the "small specialist models" thesis in late 2024, is more nuanced than it reads on Twitter. Small models lead by count, but the 13-33B band is the single most populated among models that explicitly advertise their size, suggesting that is where most fine-tuning effort actually concentrates.
This report sits next to our other 2026 ecosystem reads, including the AI SDK landscape across npm and GitHub and top AI agent repos by star velocity. Same methodology pattern: real public data, multiple cuts, no vendor framing.
Methodology
- Data sources: Hugging Face Hub API
- Time window: Snapshot taken 2026-04-29
- Sample: Top 1,000 public models on Hugging Face Hub sorted by lifetime download count, fetched via /api/models with full=true to expose tags, license, pipeline_tag, and creation date. Total accumulated downloads across the basket: 2.16B.
- Cleaning: Organization derived from the slash-prefix of the model id. License and pipeline_tag come straight from the model card. Parameter sizes are extracted by regex from the model id (e.g. 'Llama-3.1-8B-Instruct' yields 8B); 351 of the 1,000 models declare a size in their id and are included in the size-band chart. 'Eastern orgs' is a hand-curated list (Qwen, BAAI, deepseek-ai, THUDM, baichuan-inc, Alibaba-NLP, ZhipuAI, internlm, mlx-community, 01-ai, yi); the cut is approximate but conservatively biased away from inflation.
Limitations. Hugging Face download counts are inflated by mirrors, repeat CI pulls, automated benchmarking, and HuggingFace Spaces serving. They are best read as a relative popularity signal between models, not an active-user count. The inflation factor is roughly constant across organisations, so comparative ratios are robust; absolute volumes are not.
Parameter sizes are inferred from model-id strings; only 351 of 1,000 models declare a size that way, so the size-band chart represents a sample rather than the full top-1k. The sample skews toward orgs with consistent naming conventions (Llama, Qwen, deepseek, Mistral) and away from orgs with cryptic model ids (older sentence-transformers, some Hugging Face internal benchmarks).
We did not count gated or private models that the public API hides; the bias is small but tilts the count slightly away from frontier closed-weight releases. The "eastern orgs" classifier is hand-curated and will miss smaller Asian labs that have not yet broken into the top 1000.
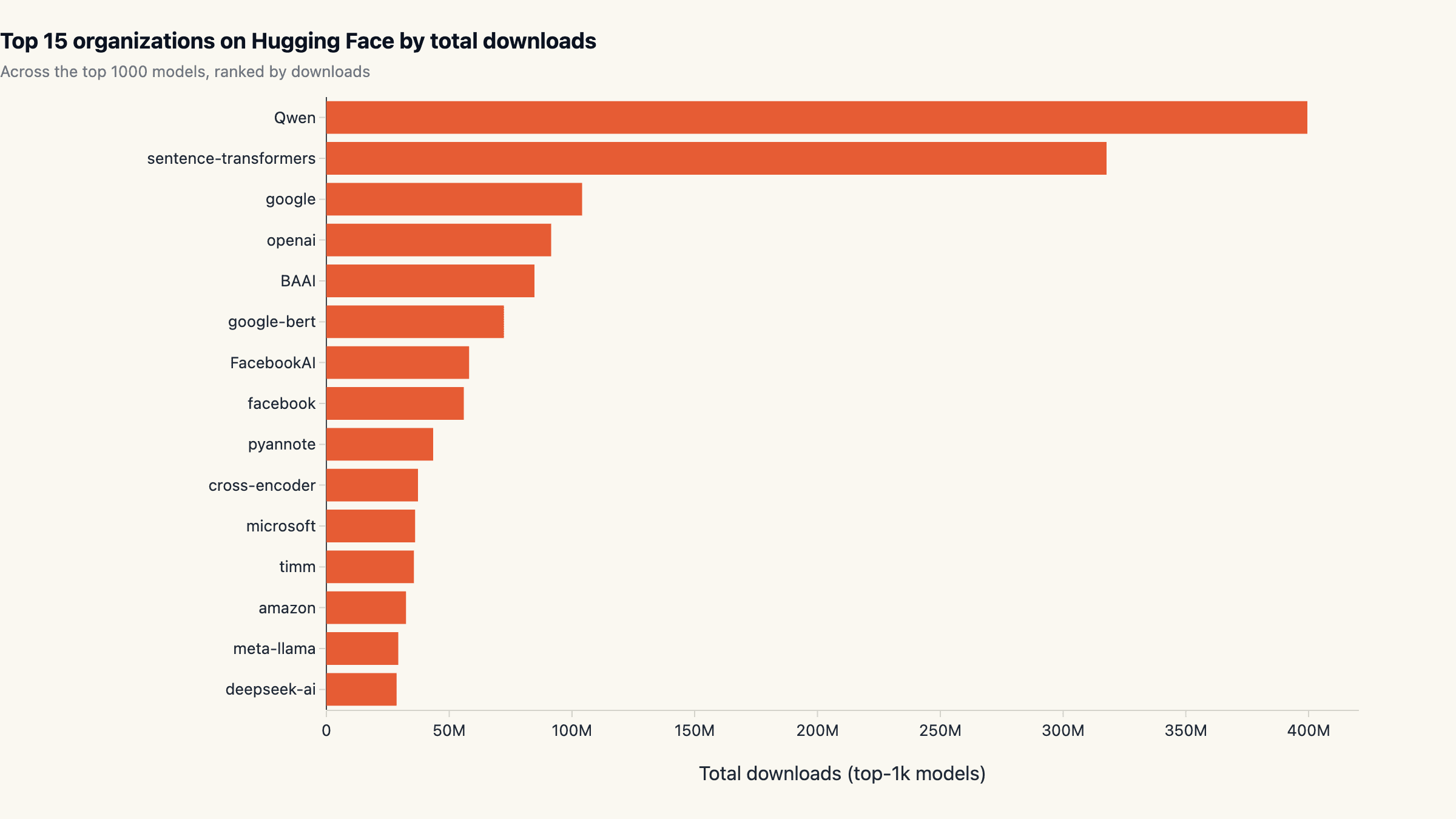
Qwen owns the Hub: 399M downloads and 4× Google's footprint
Qwen accounts for 399.4M downloads across its top models, 18.5% of the entire top-1k basket. The runner-up is sentence-transformers (a single embedding org rather than a model family) at 317.7M (14.7%), followed by Google at 104.2M (4.8%), OpenAI at 91.6M (4.2%), and BAAI at 84.7M (3.9%). The Pareto shape is striking: just five organisations concentrate 46.1% of all top-1k traffic, and the top ten capture 58.5%.
That ranking is striking on its own; the composition is what structural readers should pay attention to. Of the top 12 organisations by download volume, only three are US-headquartered closed-weight labs. The rest split between embedding-only repositories (sentence-transformers, cross-encoder, BAAI), Asian labs (Qwen, deepseek, Alibaba-NLP), and Meta's Llama family. The dominant story on Hugging Face in 2026 is open weights from non-US labs, not the closed-weight providers that get top billing in tech media.
For anyone benchmarking the qwen vs llama comparison specifically, Qwen's lead is decisive on this dataset: it pulls about 6× the download volume of meta-llama (29.6M) on the Hub. That gap reflects two factors, Qwen's wider open release pattern (most weights are Apache 2.0) and a deeper fine-tune ecosystem (more derivative models compounding the base downloads).
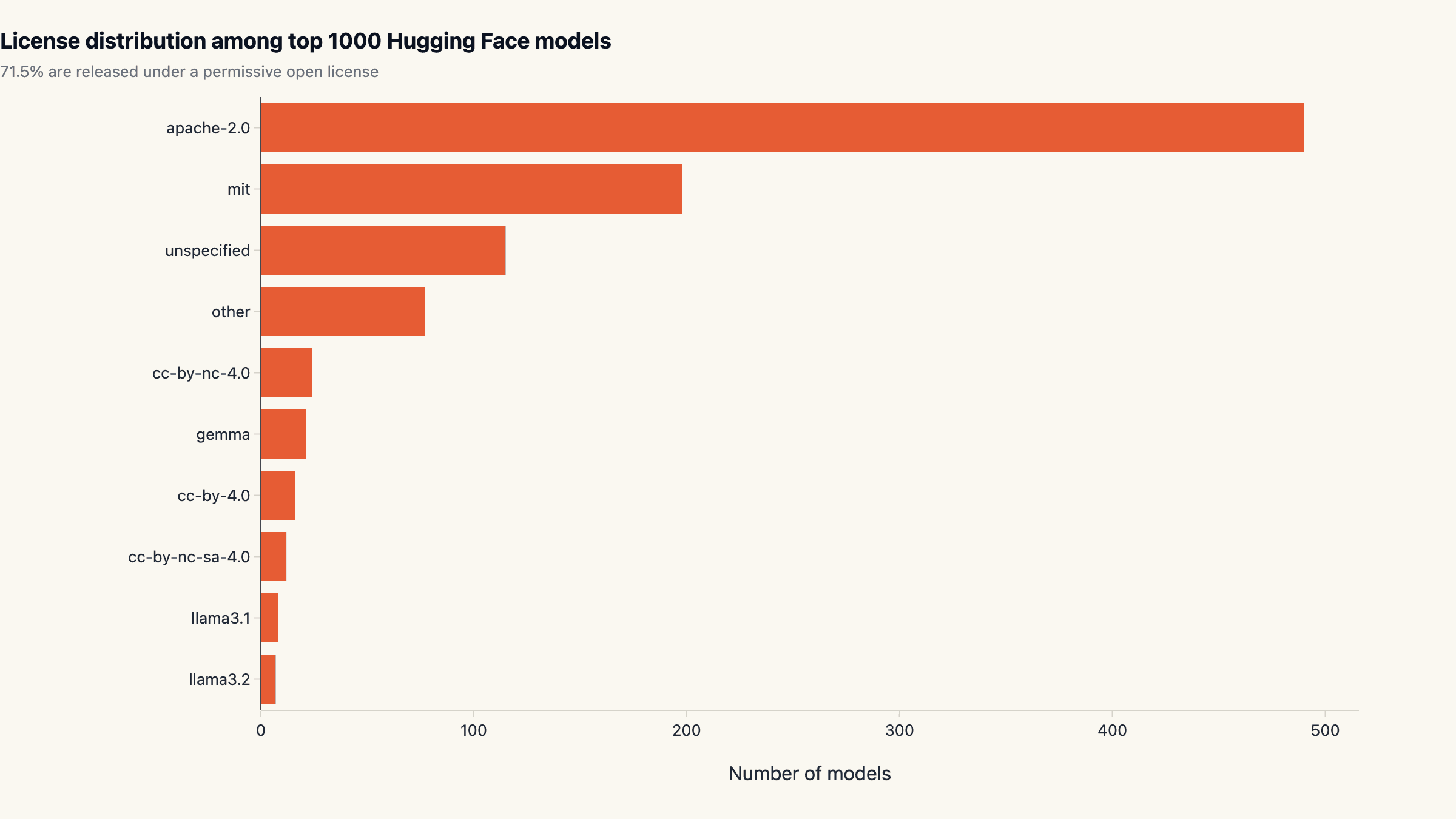
Apache 2.0 won the open-weight license war
Across the top 1,000 models, 71.5% carry a permissive open license. Apache 2.0 alone covers 490 / 1,000 (49.0%), and MIT covers another 198 / 1,000 (19.8%). Together two thirds of the top models. The rest split across "unspecified" (115), Meta's Llama family licenses, and a long tail of Creative Commons variants. The OSI-approved set has effectively standardised on Apache 2.0 as the default for serious open-weight releases.
Llama license remains a meaningful slice but is firmly second-tier on the Hub. Meta's bespoke license (which restricts derivative use for large-scale commercial deployment without separate agreement) is ergonomically heavier than Apache 2.0 for downstream fine-tuners, and that friction shows up in the data. Qwen's Apache 2.0 release strategy removed that friction entirely and is the most under-rated commercial decision in open-weight AI for 2025.
For teams choosing what to fine-tune on or productize: Apache 2.0 models give you the cleanest legal posture. The llama license is manageable but adds a layer of legal review that the Apache-flavored alternatives do not require.
The East-West shift: 24% of Hub downloads are now Eastern-org
The Hub used to be a Meta + Google + Microsoft Research show with a Hugging-Face-internal long tail. The 2026 snapshot tells a different story. Eastern organisations (Qwen, BAAI, deepseek-ai, THUDM, baichuan-inc, Alibaba-NLP, ZhipuAI, internlm, mlx-community, 01-ai) collectively account for 24.1% of all top-1k downloads, 522M out of 2.16B total.
That share is meaningfully higher than Western tech-media discourse would suggest. The structural reasons are (1) Qwen's Apache 2.0 release strategy attracts the global fine-tune audience that Llama's bespoke license partly repels, (2) deepseek's R1-style reasoning release mid-2025 produced a multi-quarter download tailwind that has not yet faded, and (3) the BAAI / Alibaba-NLP repositories ship a large catalog of embedding and instruction-tuned models that show up across many industry pipelines.
The narrative implication for vendor strategy is direct. Stack decisions that index on "Western open-weight models" miss roughly a quarter of where production load actually lives in 2026. The cleanest hedge is keeping orchestration and tooling agnostic about base model provenance, which is the same posture we recommended for the AI SDK landscape ecosystem.
Concentration: 46% of downloads in five organisations
The top-1k basket on Hugging Face is moderately concentrated. The single largest org (Qwen) pulls 18.5% of all downloads, the top 5 pull 46.1%, and the top 10 pull 58.5%. The 50%-share threshold lands somewhere between rank 6 and rank 7. Below the top 10, the curve flattens into a long tail of fine-tunes, derivatives, and specialist embeddings.
Compared to a year-ago snapshot the curve has steepened on the head and lengthened on the tail. Qwen's individual share grew the most, but the bigger structural shift is the rise of embedding- only repositories (sentence-transformers, cross-encoder) into the top tier. Embeddings were a niche slice of the Hub in 2023; in 2026 they are the second largest single source of downloads. The reason is RAG: every production retrieval-augmented system pins an embedding model and pulls it on every CI and worker spin-up, so the volume compounds.
The practical takeaway for anyone monitoring hf model downloads as an adoption signal: the basket has a dominant head plus a thick embedding tail, and ignoring either misreads the picture.
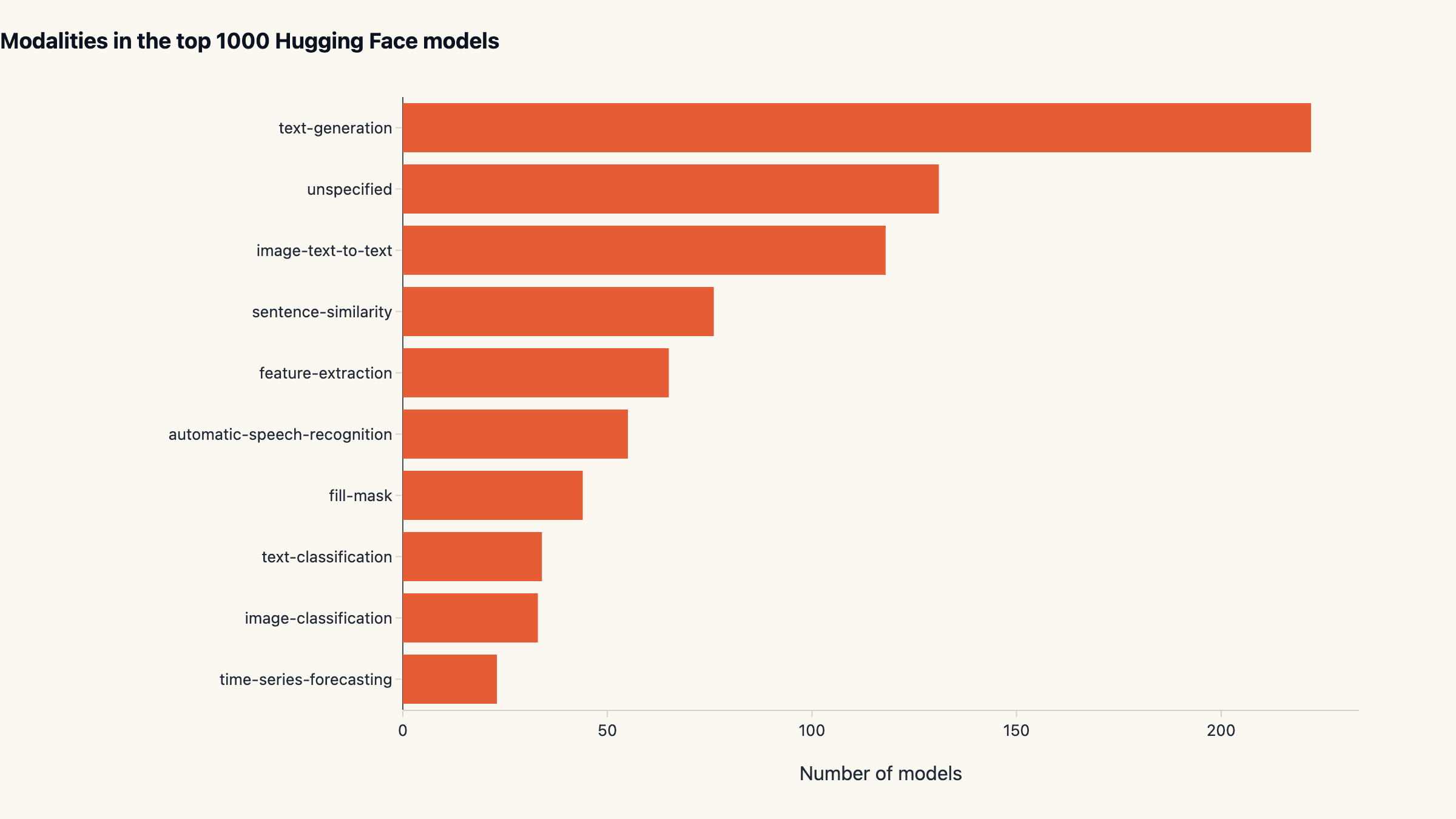
Modalities: text generation leads, multimodal is a quarter of the Hub
Among models that declare a pipeline_tag, text-generation
leads with 222 of the top 1,000 (22.2%). The second-largest
declared category is image-text-to-text at 118 (11.8%).
Vision-language models are now the second pillar of the Hub,
ahead of pure embedding (sentence-similarity, 76) and
feature-extraction (65) workloads. Speech recognition still
has a real footprint at 55 models.
The "multimodal is taking over" framing in 2025 was directionally right. In raw count, image-text-to-text (118) and image-classification (49) plus depth-estimation, image-segmentation, and the smaller categories together account for roughly a quarter of the top 1000. That is a meaningful shift away from text-only being the default Hub workload, although text-generation still leads any single pipeline_tag category by a wide margin.
For practitioners deciding what to specialise in: vision-language remains the highest-leverage second area to learn after pure-text LLM tooling. Speech recognition is a smaller market by Hub footprint but with a clearer commercial unit economics than most text-gen plays.
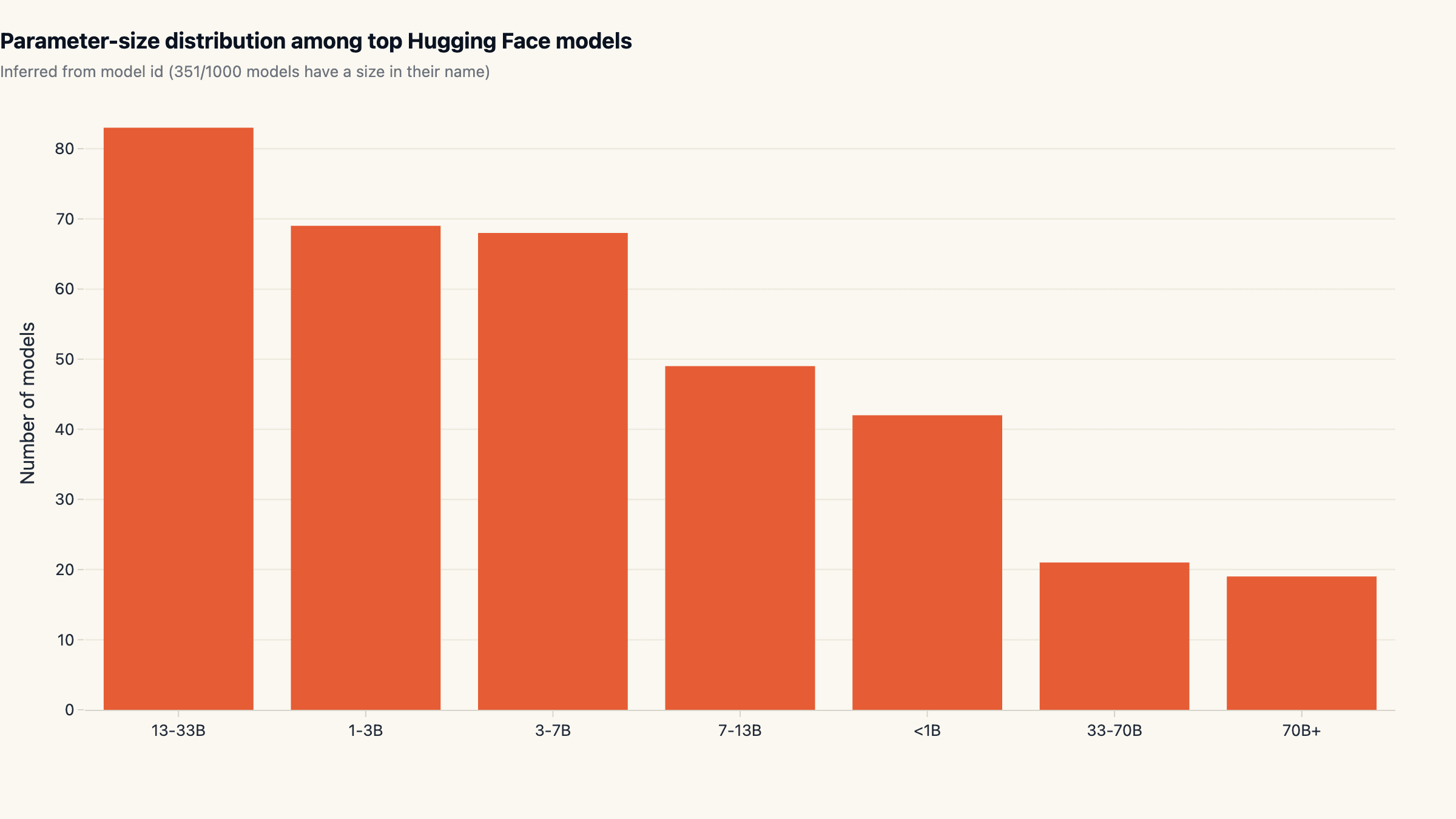
13-33B is the most populous size band
Of the 351 models that declare a parameter count in their id, the single largest band is 13-33B with 83 models (23.6%). Sub-7B totals add up to 179 models (51%), confirming the "many small specialists" pattern by raw count, but the 13-33B band is bigger than any individual sub-band. The 70B+ category is small (19 models) and dominated by Llama and Qwen heavyweight releases. 40.7% of size-named models are sub-7B, not the "vast majority" sometimes claimed.
The popular framing of "the small-model wave" is real but blurry. By number of distinct fine-tunes, mid-size (7-33B) is the most active band; by number of base architectures, sub-7B and 70B+ both have smaller dedicated families. By production deployment cost, sub-7B wins on per-request economics; by general capability, 13-33B remains the sweet spot for non-frontier work.
Selection heuristic: if you are choosing a base model for fine-tuning in 2026, default to a 13-33B Apache-licensed base unless latency is a hard constraint, then drop to sub-7B. The Hub's distribution is consistent with that bias.
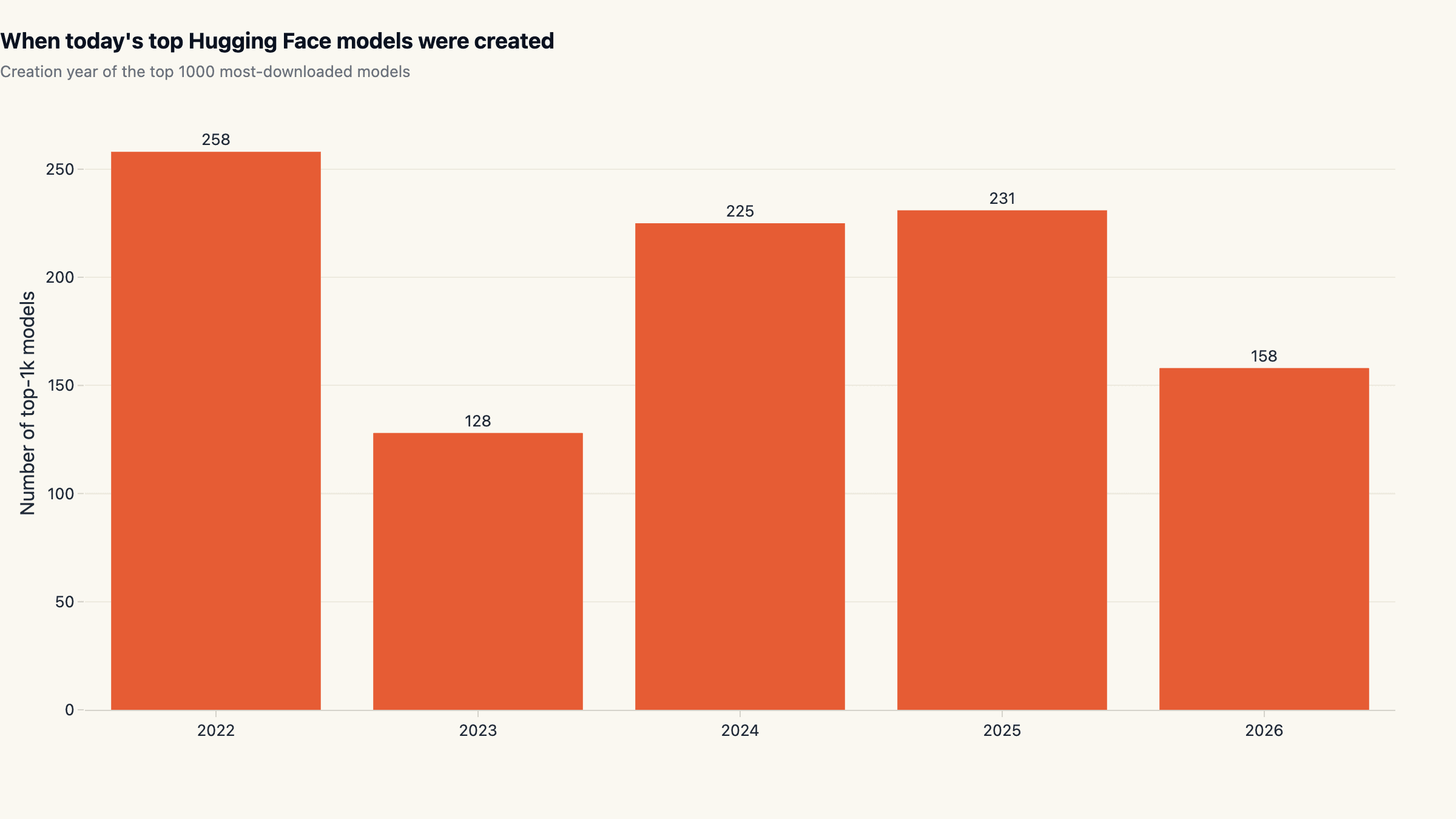
When today's top models were uploaded
The snapshot lets us look at when each of the top 1000 models was first uploaded. The cohort distribution reveals an underappreciated property of the Hub: most of today's top-downloaded models are not from this quarter or even this year. The cohort breakdown across modern years is 2022: 258, 2023: 128, 2024: 225, 2025: 231, 2026 YTD: 158. Roughly a quarter of the top 1000 were uploaded in 2022 or earlier and have accumulated downloads continuously since.
The 2023 dip and the 2024 recovery match how the field reorganised around chat-tuned models after the late-2022 ChatGPT moment. The 2025 cohort is comparable to 2024, indicating that the Hub-relevant release cadence has stabilised at roughly 200-250 new top-tier model uploads per year. The 2026 YTD count (158, four months in) is tracking ahead of that pace.
For anyone tracking the hugging face top models roster as a market signal: a meaningful fraction of the top-100 today is models that were posted in 2022 and grew into their position. Newness is not the same as relevance on this dataset.
What this means for picking a model in 2026
Three operating heuristics fall out of the data. First, default to Apache 2.0 base models for serious work. They cover 49% of the top 1000 and avoid the legal-review tax that Llama-license bases impose. Qwen's Apache strategy is the cleanest commercial example of why this matters at scale.
Second, do not anchor only on Western labs. Eastern orgs control 24% of Hub volume in 2026, and that share is not coming back. Skipping Qwen, deepseek, BAAI, and the rest of that cluster systematically under-explores the production-relevant model space. The cleanest posture is to evaluate at the model level rather than the lab-of-origin level.
Third, mid-size is the production sweet spot. 13-33B has more distinct fine-tunes than any other band on the Hub, which means more community-validated checkpoints to start from. Sub-7B is right when latency is the binding constraint; 70B+ is right when you have the hardware budget and need general-frontier capability. The middle is where most teams should default.
Teams that want to skip the GPU and serving-stack build entirely can run any of these open-weight models behind a sandboxed agent runtime; that is the path maxgent is built around. For orchestration patterns and example deployments see the use-cases gallery.
What we are not measuring
Three caveats for readers planning to act on this. Download share is not user share. A heavy-CI shop or a popular benchmarking service can register more weekly downloads than a smaller team running production traffic. Treat model-vs-model ratios as robust and absolute volumes as inflated.
Gated and private models are invisible to the public API. Any frontier closed-weight release that ships through Hugging Face but requires authentication does not appear in this dataset. The most affected slot is the high-end Llama tier (Llama-3.x and the licensing-restricted variants); a fully gated dataset of those would shift the Eastern-org share lower by a few points.
The top 1000 cuts off a meaningful long tail. Specialist embedding models, domain-tuned medical or legal LLMs, and recent releases from smaller labs sit just below the cutoff and would change the modality and parameter-size distributions if included. A wider-basket version of this analysis (top 5000) is on the roadmap and will run quarterly alongside this report.
We will refresh this dataset every three months. The slug is permanent; subsequent versions will appear as updates rather than new URLs, so any backlinks to this report stay valid as the numbers evolve.
Cite this research
maxgent (2026). Hugging Face Hub State 2026: Qwen Leads, Apache 2.0 Wins, Mid-Size Models Dominate. https://maxgent.ai/blog/huggingface-hub-state-2026/
Charts and data are released under CC-BY 4.0. Please link back when reusing.
Dataset & charts
All data and charts released under CC-BY 4.0. Please link back when reusing.
Raw data
Embeddable charts
- creation-cohorts.html 2.9 KB
- license.html 2.8 KB
- modalities.html 2.8 KB
- size-bands.html 2.8 KB
- top-orgs.html 3.0 KB
Want one of these charts on your blog or report? Click Copy embed next to any chart to copy a ready-to-paste HTML snippet (with attribution), then paste it into your page.
MoClaw Research publishes quarterly data studies on the AI tools ecosystem, drawing on public registries (npm, GitHub, Hugging Face, arXiv, Google Trends). All charts and datasets ship under CC-BY 4.0.
Ready to automate with AI?
MoClaw brings AI agents to the cloud. No setup, no coding required.
References: Hugging Face Hub API